La 15ème journée franco-suisse en veille et intelligence économique aura lieu jeudi 14 juin 2018 à Besançon à la COMUE (Communauté d’universités Bourgogne – Franche-Comté) : et s’intitulera « Quelle veille pour les start-ups ? »
Ainsi, ce workshop proposera d’apporter aux entrepreneurs et à leurs accompagnateurs des points de repère méthodologiques leur permettant de structurer une démarche de recherche d’informations et de veille, en l’articulant tout au long du processus entrepreneurial, avant mais aussi après la mise en marché. Il sera illustré par des exemples de projets innovants dans des secteurs d’activité variés, en BtoC et BtoB. Il mettra l’accent sur les outils libres et l’exploitation des données digitales. Deux cas proposés par les participants seront traités lors de la journée, permettant aux participants de s’approprier la démarche et de découvrir les méthodes et outils de veille adaptés aux start-ups.
Programme prévisionnel :
9h00 Accueil, café
9h30 Présentation de la journée et mots d’accueil
9h45 Quelle veille pour les start-up : les besoins d’information associés au
processus entrepreneurial, Pascale Brenet
10h30 Préparation de l’atelier de l’après-midi. Frédéric Martinet
10h40 Projet « Métabsorber » : la démarche de recherche d’informations d’un
projet innovant issu de la recherche, Ali Yacin El Ayouch et Youssef Tejda
11h10 Pause
11h30 Quels outils et quels soutiens pour la veille des start-up technologiques à
Neuchâtel ? Sandy Wetzel et Dr. Khalid Zahouily
12h00 Déjeuner
14h15 Quelles prestations pour les start-up clientes de centre Doc ? David Borel
15h00 Retour sur les 2 cas choisis le matin : proposition de mise en place d’une
veille. Frédéric Martinet
16h00 Synthèse et conclusions
Inscrivez-vous ici. Cf le site de la Journée de la Veille.
Le crowdfunding, terme anglais pour désigner un « financement participatif », a connu un essor grâce aux réseaux sociaux et est désormais essentiel dans la vie quotidienne d’une ONG.
Ainsi, les sites de financement participatif permettent aujourd’hui à tout un chacun de contribuer à un projet, de financer une bonne idée, en se basant sur ce principe simple : si l’on se rassemble pour donner – même un peu -, on multiplie l’impact de nos contributions.
C’est donc un moyen simple de faire participer et fédérer une communauté sur un objectif commun. « Le financement participatif bouscule l’économie !Pour libérer la créativité » comme le dit si bien Vincent Ricordeau, Co-fondateur et président de Kisskissbankbank.
Pour l’ONG Shark Citizen, j’ai eu ainsi l’occasion d’utiliser la plateforme participative, Ekosea.com dédiée au monde maritime et à l’environnement. Le projet était de collecter de l’argent pour observer la nurserie de bébés requins pointes noires du nord de Mayotte à l’aide d’un drone.
L’objectif a alors été atteint avec plus de 2080 euros collectés sur un objectif de 2000 euros ! Sans les donateurs nous n’aurions jamais pu observer et comprendre les comportements du requin sur Mayotte. Cela démontre bien l’engagement et le pouvoir des communautés de passionnés. De plus, on remarque bien la nécessité pour une ONG de se tourner vers le crowdfunding en parallèle à des actions mises en place sur les dons en ligne.
Cependant, il faut bien choisir en amont sa plateforme car elles comportent différentes modalités et formes de transactions.
Source : Guide AEC, « le financement participatif, une alternative à le levée de fonds
On distingue ainsi 3 grandes familles de plateformes participatives :
Plateforme de dons avec ou sans contrepartie : Le don est alors désintéressé et intemporel dans le premier cas. Le don avec contrepartie consiste à donner à un projet, en échange d’un retour. Ainsi, les collectes durent un temps limité pendant lequel les participations se cumulent dans le but d’atteindre ou de dépasser l’objectif minimal déterminé par l’auteur ou le producteur du projet. C’était par exemple le cas pour mon association Shark Citizen avec Ekosea.
Plateformes de prêts rémunérés ou non : Le prêt aux entreprises ou crowdlending est une forme de prêt accordé par des particuliers avec un remboursement des intérêts étalé dans le temps. L’approche est différente du crowdfunding, car le prêteur (épargnant) n’est pas un donateur. Il vient se substituer aux banques pour financer le projet d’une entreprise. Dans le second cas, des particuliers prêtent de l’argent, sans intérêts, à d’autres particuliers ou à des entrepreneurs. Ces prêts sont réalisés alors sans intention de profit puisqu’ils sont remboursables sans intérêts.
Plateformes d’investissement : Il s’agit d’une prise de participation contre une rétribution financière obtenue par des dividendes, royalties ou plus-values éventuelles réalisées lors de la revente des titres.
Vous trouverez également ci-dessous une infographie plus détaillée avec les différentes plateformes classées par typologie de famille. Vous pouvez cliquez sur l’image pour l’agrandir.
Source : http://financeparticipative.org/
Ensuite, pour entrer un peu plus dans les détails et voir ce que proposent chaque plateforme, vous trouverez un bon tableau qui effectue un comparatif des 8 plateformes les plus utilisées actuellement lors de campagnes participatives : comparatif de 8 plateformes de crowdfunding.
Le tableau recense les principaux points, à savoir :
Nom
Descriptif
Année de création
Type de financement
Type de projet
Spécificités
Contreparties
Montant min et max
Objectif moyen
Montant total collecté
Conditions financières
Conditions particulières
Fiscalisation des fonds collectés
Edition des reçus fiscaux par la plateforme
Don total moyen
Durée d’une campagne
% de réussite
Public
Versement
FAQ, blog, guide utilisateur
Autres informations
Vous trouverez ci-joint quelques liens intéressants sur cette thématique de crowdfunding :
Voilà, derrière des projets qui réussissent à mobiliser des dons, se cachent beaucoup de travail et un plan de communication bien ficelé. Il est essentiel de faire un focus là-dessus et je ferai donc dans peu de temps un prochain billet sur la planification à entreprendre pour être prêt le jour J du lancement d’un projet participatif.
Voici la suite de l’article « vers un Web de données » qui abordait l’histoire du Web, les principes architecturaux du Web et les grands principes du web de données : URL, URI, IRI.
De la page à la ressource :
Ce qui n’a pas changé au cours de ces évolutions, c’est le R, c’est à dire la notion de ressource. Cette notion de ressource est large sur le Web et ne se limite pas aux pages, images ou vidéos que l’on peut avoir sur le Web. Ainsi, on nommera « ressource » tout élément que l’on peut identifier à travers un URI : URI à ma voiture, URI à un lieu, URI à un bâtiment. Nous pouvons donc identifier n’importe quoi avec ce système et décrire toutes ces choses qui sont autour de nous et les échanger dans autant de langages que l’on veut.
Source : MOOC Web Sémantique
Les URI sont donc utilisées pour nommer des choses très variées.
Nous avons donc moyen d’échanger les données mais la question se posera maintenant de les publier et de les lier. Rentre alors en jeu la ratatouille, où plutôt la datatouille !
Je m’explique : Une bonne ratatouille a pour principe de faire cuire un par un les légumes. Cuisinés un à un, on les mélange par la suite pour faire notre ratatouille. Ainsi, un des intérêts est que ce n’est pas uniquement un plat en lui-même mais un plat qui peut être utilisé comme ingrédient pour faire d’autres plats.
Source : MOOC Web sémantique
Si on revient alors à nos moutons, c’est la même chose pour le web de données liées. Il suffira pour cela de remplacer les différents ingrédients par des bases de données et choisir les données que l’on voudra publier et qui seront réutilisées par d’autres : données géographiques IGN, données statistiques INSEE…
Source : MOOC Web sémantique
Ainsi, par exemple les données qui décrivent le canapé sur lequel je suis assis par exemple pointeront vers les données de la salle dans laquelle se trouve ce canapé. Les données du canapé seront liées aux données de la salle. Vous la voyez la datatouille ?
Si on entre plus précisément dans le vif du sujet en utilisant les protocoles voici ce qu’il en est :
« Imaginons qu’un utilisateur lambda sur le Web rencontre un URI. Il fait une première vérification : est-ce qu’il s’agit d’un URI HTTP, c’est à dire un URI qui peut être interrogé sur le Web ? Si c’est le cas, il va utiliser le protocole HTTP pour faire un GET sur cet URI, une requête en disant « Qu’est-ce que c’est? » La réponse du serveur va varier. Si c’est un utilisateur qui est devant un navigateur, le serveur va lui renvoyer une page Web lui décrivant le sujet de cette URI. Si c’est un logiciel, téléphone mobile, GPS, le serveur va pouvoir lui renvoyer pour la même requête sur le même identifiant non pas une page Web mais des données XML que le logiciel pourra intégrer à sa base et utiliser pour proposer de nouvelles fonctionnalités » (MOOC Web Sémantique).
Comment choisir des URI pour nommer des choses dont on veut parler sur le Web ?
Il n’y a pas de réponse unique. Voir à ce sujet les deux ressources ci-dessous du W3C mais en théorie, on peut transformer tout identifiant en URI en choisissant un nom de domaine et un schéma d’URI.
Les standards vont nous permettre de publier, d’interroger, tracer les différentes données sur le Web. La pile ci-dessous se lit de bas en haut, des URI jusqu’aux utilisateurs.
Source : MOOC Web sémantique
Source : MOOC Web sémantique
IDENTIFICATION : Identifiants URI et URI.
REPRESENTATION : représentation des données que nous échangeons sur le Web. Le standard utilisé est RDF, Resource Description Framework.
REQUÊTES : Une fois les données publiées, nous les interrogerons. Ainsi, pour écrire ces requêtes, les échanger et avoir des résultats on utilisera le langage SPARQL qui permet de sélectionner des sous-parties de données publiées sur le Web, qui nous intéressent selon les critères que l’on veut donner.
RAISONNEMENT : Publication des schémas de ces données : 2 langages sont utilisés : RDFS pour échanger des schémas très légers et OWL pour nous permettre plus de formalisation en logique.
CONFIANCE : Traçage des données, vérification des sources et si oui ou non on peut leur faire confiance. Le langage PROV suit les données, leur provenance et les traitements qu’elles ont subis.
INTERACTION : Avec l’utilisateur final. Proposition de nouveaux services, interactions aux utilisateurs lorsqu’ils utilisent le Web et naviguent quotidiennement.
Voilà, ce billet s’achève sur les standards utilisés dans le Web. Le MOOC aborde par la suite la deuxième brique de cette pile avec le modèle RDF, la première étant les URI que nous avons vu dans ce billet et introduit dans mon premier billet à ce sujet.
Attention pavé ! Écrit par Olivier Andrieu, l’un des plus grands spécialistes du référencement, cet ouvrage de référence (réédition février 2018) fournit toutes les clés pour garantir à un site Internet une visibilité maximale sur les principaux moteurs de recherche.
Description :
Ainsi, on revient à la base mais c’est toujours bien de se plonger dans l’historique et le fonctionnement de Google. Cette dernière édition aborde aussi les dernières tendances (SEO international, Mobile First, cocon sémantique, featured snippets…). Cependant, certains le trouveront répétitif et fait de copiés-collés d’éditions précédentes…
600 pages quand même me direz-vous mais la clarté, les nombreux exemples et la pédagogie feront que sa lecture sera aisée. Il est en tous les cas moins soporifique que d’autres livres sur le même sujet.
Même si vous ne connaissez pas le nom de l’auteur vous devez forcément connaître son site, Abondance.com qui publie quotidiennement infos et actualités sur le SEO depuis 1998.
Ce message s’adresse tout particulièrement à mes étudiants en communication / Web qui me posent très souvent des questions sur le référencement. Vous êtes parés pour aborder le monde merveilleux du SEO 🙂
Clément Rosset, philosophe français disparu fin mars 2018 : un bon et vrai vivant, jamais pédant, plein d’humour.. nous avons plus que jamais besoin de ses livres actuellement.
Ne prenez pas peur au terme « philosophie » car il est accessible ! Un des ouvrages de Clément Rosset, « La Force majeure » est d’ailleurs un de ceux que je conseille pour celui qui veut débuter dans ses oeuvres.
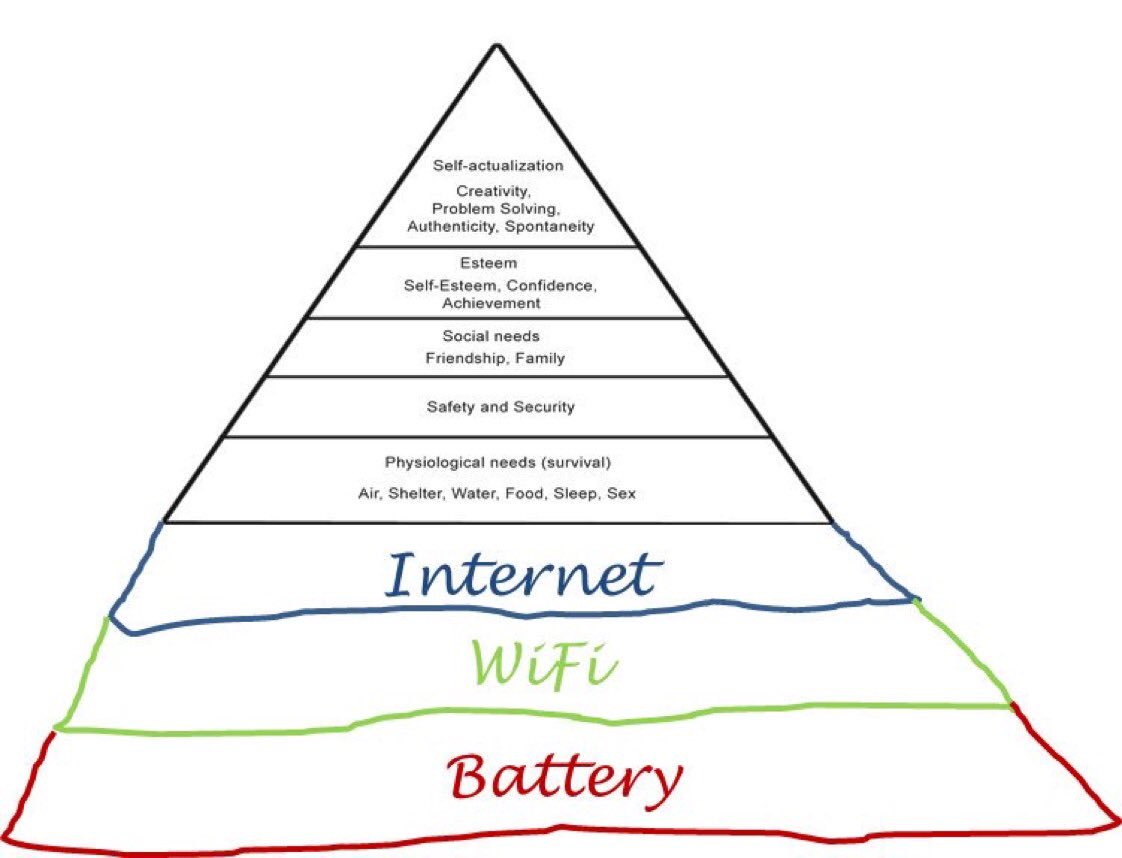
Réactualisation de la pyramide de Maslow sur la distinction des besoins. Tellement vrai pour beaucoup d’entre nous !
AnimaVeille est spécialisée en veille stratégique, veille concurrentielle et veille E-reputation. Elle est dirigée par Stéphanie Barthélémi, consultante indépendante et blogueuse depuis 2004.
Gérer le consentement
Pour offrir les meilleures expériences, nous utilisons des technologies telles que les cookies pour stocker et/ou accéder aux informations des appareils. Le fait de consentir à ces technologies nous permettra de traiter des données telles que le comportement de navigation ou les ID uniques sur ce site. Le fait de ne pas consentir ou de retirer son consentement peut avoir un effet négatif sur certaines caractéristiques et fonctions.
Fonctionnel
Toujours activé
L’accès ou le stockage technique est strictement nécessaire dans la finalité d’intérêt légitime de permettre l’utilisation d’un service spécifique explicitement demandé par l’abonné ou l’utilisateur, ou dans le seul but d’effectuer la transmission d’une communication sur un réseau de communications électroniques.
Préférences
L’accès ou le stockage technique est nécessaire dans la finalité d’intérêt légitime de stocker des préférences qui ne sont pas demandées par l’abonné ou l’internaute.
Statistiques
Le stockage ou l’accès technique qui est utilisé exclusivement à des fins statistiques.Le stockage ou l’accès technique qui est utilisé exclusivement dans des finalités statistiques anonymes. En l’absence d’une assignation à comparaître, d’une conformité volontaire de la part de votre fournisseur d’accès à internet ou d’enregistrements supplémentaires provenant d’une tierce partie, les informations stockées ou extraites à cette seule fin ne peuvent généralement pas être utilisées pour vous identifier.
Marketing
L’accès ou le stockage technique est nécessaire pour créer des profils d’internautes afin d’envoyer des publicités, ou pour suivre l’utilisateur sur un site web ou sur plusieurs sites web ayant des finalités marketing similaires.